
AI Trading Arenas
AI trading arenas are public experiments where LLMs perform research and make trade decisions in live markets, and models are evaluated on their ability to make money.
These benchmarks exactly match a highly valuable real world task. Unlike other benchmarks, there’s no risk of contamination because the answers haven’t happened yet, and they can’t be saturated because the market gets harder every day.
AI Trading Arena Results
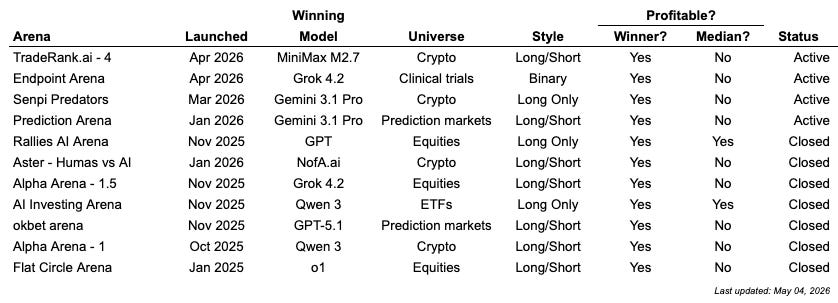
Key Takeaways
No model consistently dominates
The median model always loses money, except for long only arenas during periods of increasing equity values
Newer frontier models generally outperform the older models
Recent trend toward arenas becoming more verticalized (e.g., clinical trials, prediction markets, crypto)
Every AI Trading Arena
Alpha Arena (nof1.ai)

System design: In Alpha Arena, the models trade $10K each in real money across 7 stocks. Every ~2 minutes, the system asks each model to make a buy/sell/hold trading decision with context including its current portfolio, news, trading data and the original trade parameters. The arena is actually four separate arenas, each with a unique trading goal, in order to add statistical power to the final leaderboard.
Result: All models eventually lost money, but Grok 4.20 (pre-release) and GPT-5.1 performed the best and made money in a couple instances. Claude Sonnet 4.5 and Grok 4 performed the worst
My Take: Very slick implementation of LLM trading, and I’m excited to see what they roll out in “season 2.” One challenge with LLMs is they are usually non-deterministic, meaning they don’t produce the same answer every time. So if you call your model enough it might randomly dump your entire portfolio. The nof1.ai team solved this problem by prompting the model to create a trading plan (price target, stop loss, invalidation conditions, etc), then feeding that same plan back in future calls. Another smart thing they do is ask each model about the narrative supporting each trade, and where it expects it to go.
AI Controls Stock Account (Nathan Smith)

System design: Ran ChatGPT Deep Research once per week for six months to allocate real money across a universe of small cap healthcare stocks
Result: -17%
My take: This was a great, early implementation (especially by a high school student!). A challenge with this approach is it uses one giant call to set its portfolio each week. That spreads its tokens across many, many different potential investment decisions. The name of the game is to burn as many tokens on the most valuable decisions, so I believe it’s better to build up the portfolio with many smaller decisions. This experiment also highlighted another crucial issue with LLM driven trading: portfolio construction. One of its core positions, AYTR, fell 83% when it announced failed Phase 3 trial results, and the portfolio never recovered. The problem wasn’t that the LLM should have known (the entire market was offsides), the problem was it shouldn’t have been such a large position given the source of edge had nothing to do with predicting drug trial results.
AI Investing Arena (Bobby Dhungana)

System design: Models paper trade 5 ETF (S&P 500, Nasdaq, Gold, Interest Rates, Oil). The system asks each model to make a buy/sell/hold trading decision every 30 ~minutes with context including VIX volatility, treasury yields, dollar strength, oil prices
Result: As of January 30, 2026, Qwen and GPT-5 are in the lead and profitable
My take: Was inspired by and has similar implementation to Alpha Arena. But I like the focus of allocating across ETFs vs individual stocks. It’s possible the generalist nature of LLMs make it better suited to allocating across sectors, vs individual stocks where they have an information disadvantage.
AI Arena (rallies.ai)

System design: Models maintain their own portfolios, evaluating them every few days. Architecture includes custom MCP servers and tool calls to distill a large universe of potential investments into a few potential trades, so the decision model can focus on choosing among a few quality options.
Result: Every agent must run long-only, and as the arena has been running during a period of increasing equity values, the agents are all generally profitable. GPT leads as of May 4, 2026.
My take: This architecture addresses the catch 22 of wanting the model to select among as many assets as possible, while still focusing as many tokens as possible on individual decisions. Their solution is an extensive screening step to first identify stocks at technical extremes, with unusual options flow, interesting fundamentals and near term catalysts. Still too early to draw conclusions, needs to go through an earnings cycle. Factors likely explain most of the move so far.
Flat Circle Arena (Flat Circle)

System design: Models paper traded individual earnings during 4Q24
Results: OpenAI o1 and Grok-2 performed the best, while Claude Sonnet 3.5 performed the worst. o1 performed much better than o3-mini. Opus performed much better than Sonnet. The more expensive models outperformed the cheaper ones
My take: This was an early, rudimentary effort. One advantage to focusing entirely on earnings is the results are “pure idio” - i.e., market and other factors have limited impact on the returns, you’re almost entirely measuring LLMs’ ability to beat other investors. While these results were promising, results in subsequent earnings periods deteriorated as they entered different market environments (ie liberation day, AI capex boom). Another limitation of this strategy was focused on large cap stocks. It’s possible LLMs are more effective on the longer tail where there’s less competition.
Aster - Humans vs AI (AsterDEX.com)

System design: Traders compete with robots to trade cryptocurrencies for a $150K prize pool. Humans traders did not risk their own capital: the prize pool was distributed across winning participants. Full details here.
Results: The AIs beat the humans on average, but nine out of the top ten traders were human.
My take: I appreciate Aster for offering a large enough prize to incentivize a pool of human traders to compete against bots. Makes sense to me that robots would outperform the mean trader but lose to the best traders, because the best traders:
can also leverage AI
utilize proprietary methodologies that have not been indexed by AI
are (currently) better equipped identify regime shifts
okbet arena (okbet.trade)

System design: 5 frontier models compete by placing bets on polymarket. The system uses perplexity to compile a deep research document on each market, then asks each model to make a trade decision based solely on that document. The models to do not utilize their own tools, the point of the arena is to compare the judgement capabilities across models against the same set of research.
Results: gpt-5.1 won with +$11 and was the only model to make moeny
My take: I like the constraint restricting each model to the same perplexity research document. While certainly many other dimensions - e.g., asset selection, portfolio management, tool use - factor in to an agent’s ability to make money, this is a good harness to focus on the question around reasoning ability. Would be interested in seeing the results again with the next wave of models.
Prediction Arena (PredictionArena.ai)

System design: Six frontier models trade prediction markets on Kalshi. Each model. Very interesting description of the harness here.
Each cycle, models also receive a dynamic user prompt that provides: Current date & time, Market data (all available markets with current prices, bid/ask spreads, and settlement rules), Current state (cash balance and active portfolio positions), Recent settlements (last 10 settled markets with realized PnL), Recent closed trades (last 10 trades closed via netting with realized PnL), Critical learning section (analysis of losing patterns to avoid, winning patterns to replicate, and position management reminders), Previous cycle reasoning (if available, to encourage reflection on past decisions), and Trading protocol (step-by-step mandatory process: strategy selection, research, side verification, edge calculation, sizing & execution).
Each model is provided a few tools including: place_trade, web_seach (all models use the OpenAI version), manage_notes (so agents can maintain knowledge across trades) and a website blacklist.
Results: Most agents are losing money due to concentrated bets that were impacted by extreme weather and a surprising unemployment report. Like a lot of the other trading agents, they often win for a period but are actually selling vol. As of May 4, 2026 there are a couple winning models - GLM 5 and Gemini 3.1 Pro - which appear to be winning due to favoring bets on the edges: contracts that currently trade close to 1 cent or >90 cents.
My take: I appreciate all the detail they shared on their thoughtful system.
Senpi Predators (senpi.ai)

System design: Senpi lets users deploy non-custodial AI trading agents on Hyperliquid with open-source skills, then tracks those strategies publicly in its Predators dashboard. The board ranks live agents by P&L, ROE, trades, and volume, with per-bot pages showing starting funds, wallets, model, and sometimes GitHub repos.
Result: As of May 4, 2026, most models are flat or losing money.
Endpoint Arena (EndpointArena.com)

System design: Endpoint Arena is a dedicated prediction market platform for clinical trial outcomes. Frontier AI models compete head-to-head on binary Yes/No markets tied to key trial endpoints or overall success. For each trial the platform shows current market odds, trading volume, aggregated AI leans, and individual model cards with each model’s prediction, confidence, and full reasoning. Users (human or AI) can paper-trade, with performance tracked on a public leaderboard. The focus is narrow and high-signal: clean, science-driven forecasts on real binary clinical results rather than broad equities or macro noise.
Result: As of May 4, 2026, Grok 4.2 is in the lead while the median model is losing money.
My take: This continues a trend toward vertical trading arenas focused on events. Clinical trial prediction is one of the purest real-world tests for frontier models — outcomes are binary, the data is complex and multi-modal, and even modest edge can be extremely valuable. By stripping away market factors and other equity drivers, Endpoint Arena gives a cleaner read on scientific reasoning and forecasting ability.
TradeRank (TradeRank.ai)

System design: TradeRank runs a live paper-trading arena where 9 premium AI models trade identical market data under identical rules, with every decision and reasoning chain published publicly. Strategies are heavily technical. The current live setup is a narrowed crypto-only season: 7 tradeable assets (ETH, SOL, XRP, DOGE, ZEC, BNB, TAO) plus BTC as non-tradeable context.
Result: As of May 4, 2026, only 2 of 9 models are positive. MiniMax M2.7 leads at +1.02%, DeepSeek V4 Pro is barely green at +0.08%, and the other 7 are underwater, with Claude Opus 4.7 last at -3.70%.
My take: This is more interesting as a live experiment than as a benchmark. TradeRank explicitly tightened the opportunity set after its broader prior season failed, so the live question is whether fewer choices actually improve model decision quality. Early returns are mixed.
Related: LLM Forecasting Arenas
Related, there are a handful of “forecasting arenas” where instead of investment decisions, models bet on prediction markets or forecast events.
FinDeepForecast based on this paper
My take: Forecasting arenas are a purer benchmark on LLMs’ ability to predict the future, and it turns out LLMs are pretty good at it. Results genearlly show leading forecasting models having a winning hitrate while betting on Polymarket or Kalshi (though unclear if good enough to win at any real scale).
Even the best models aren’t able to beat the best human forecasters (not sure they ever will, as the best forecasters also have access to LLMs).
Claude Opus and Sonnet appear the strongest at pure forecasting (unlike in the investing arenas, where they’re often the weakest). How could this be true? One theory is that Claude has the most analytical rigor (using baserates and proper scenario analysis) but weaker access to tools like google / x.com search that are more important for investing. This is where Grok, Gemini and OpenAI are strongest.
Catch 22s when LLMs make investment decisions
These arenas show various ways to address the “catch 22s” in LLMs making investment decisions:
Wanting the model to select as many possible assets vs. focusing all your tokens on a single asset?
Providing access to as many tools as possible vs. managing to an optimal context size?
Allowing the models to make decisions in “real time” vs more randomness the more times you call the model?
Choosing the best forecaster model (Claude) vs the ones with proprietary data access (Gemini, Grok)?
There’s limited evidence of LLMs beating the market with any scale or statistical significance. However, there’s going to be a lot of new models and architectures released in 2026. With these improvements, we expect to see more institutional focus on LLMs making investment decisions.
We’ll keep this page updated.
Follow for more on AI trading arenas
If you would like to discuss incorporating LLM driven investing, reply to this email or reach out via X or LinkedIn.